函数式编程
思考#
- 函数式编程思维
- 函数时编程常用的核心概念
- 当下函数式编程最热的库
- 函数式编程的实际场景
函数式思维#
范畴论#
- 函数式编程是范畴论的数学分支是一门很复杂的数学,认为世界上所有概念体系都可以抽象出一个个范畴
- 彼此之间存在某种关系概念、事物、对象等等,都构成范畴。任何事物只要找出他们之间的关系,就能定义
- 箭头表示范畴成员之间的关系,正式的名称叫做"态射",(norphismy 。范畴论认为,同一个范畴的所有成员,就是不同状态的”变开形”(transformation) 。通过"态射",一个成员可以变形成另一个成员。
函数式编程的基础理论#
- 数学中的函数书写如下形式f(X)=Y。 一个函数F,已X作为参数,并返回输出Y。这很简单,但是包含几个关键点:函数必须总是接受一个参数、函数必须返回值、函数应该依据接收到的参数(如X) 而不是外部环境运行、对于给定的X只会输出唯一的Y。
- 函数式编程不是用函数来编程,也不是传统的面向过程编程。主旨在于将复杂的函数符合成简单的函数(计算理论,或者递归论,或者拉姆达演算)。运算过尽量写成一系列嵌套的函数调用
- 通俗写法function xx(){}区别开函数和方法。方法要与指定的对象绑定、函数可以直接调用。
- 函数式编程(Functional Programming)其实相对于计算机的历史而言是一个非常古老的概念,甚至早于第一台计算机的诞生。函数式编程的基础模型来源于λ(Lambda x=>x*2)演算, 而λ演算并非设计于在计算机上执行,它是在20世纪三十年代引入的一套用于研究函数定义、函数应用和递归的形式系统
- JavaScript是披着C外衣的lisp。
- 真正的火热是随着React的高阶函数而逐步升温。
注意
- 函数是一等公民。所谓”第一等公民”(first class) ,指的是函数与其他数据类型一样,处于平等地位,可以赋值给其他变量, 也可以作为参数,传入另一个数,或者 作为别的函数的返回值。
- 不可改变量。在函数式编程中,我们通常理解的变量在函数式编程中也被函数代替了:在函数式编程中变量仅仅代表某个表达式。这里所说的变量是不能被修的。所有的变量只能被赋一次初值
- map & reduce他们是 最常用的函数式编程的方法。
danger
- 函数是”第一等公民”
- 只用”表达式",不用"语句"
- 没有"副作用"
- 不修改状态
- 引用透明(函数运行只靠参数且相同的输入总是获得相同的输出)identity=(i)=>{return i} 调用identity(1)可以直接替换为1该过程被称为替换模型
专业术语#
纯函数
定义:对于相同的输入,永远会得到相同的输出,而且没有任何可观察的副作用,也不依赖外部环境的状态”。
var XS =[1,2,3,4,5];// Array.slice是 纯函数,因为它没有副作用,对于固定的输入,输出总是固定的xs.slice(0,3);xs.slic(0,3); xs.splice(0,3);xs.splice(0,3);优缺点
纯函数不仅可以有效降低系统的复杂度,还有很多很棒的特性,比如可缓存性(第一次计算会慢一点,第二次计算时有了缓存,速度极快)
在不纯的版本中,checkage不仅取决于age还有外部依赖的变量min。纯的checkage把关键数字18硬编码在函数内部,扩展性比较差,柯里化优雅的函数式解决。
//不纯的var min = 18var checkage = age => age > min; //纯的var checkage = age => age > 18;纯度和幂等性
- 幂等性是指执行无数次后还具有相同的效果,同一的参数运行一次函数应该与连续两次结果一致。幂等性在函数式编程中与纯度相关,但有不一致。
- Math.abs(Math.abs(-42))
偏应用函数
传递给函数一部分参数来调用它,让它返回一个函数去处理剩下的参数。
偏函数之所以“偏”,在就在于其只能处理那些能与至少一个case语句匹配的输入,而不能处理所有可能的输入。
//帯一个凾数参数和垓函数的部分参数const partial= (f,...args) => (..moreArgs) => f(..args,...moreArgs)const add3= (a, b, c) => a+b+C//偏立用'2'和'3'到‘add3'给你一个单参数的函数const fivePlus = partial(add3, 2, 3)fivePlus(4)//bind实现const add1More = add3.bind(null, 2, 3) // (c)=>2 + 3 + C
函数的柯里化
柯里化(Curried)通过偏应用函数实现。它是把一个多参数函数转换为一个嵌套一元函数的过程。
传递给函数一部分参数来调用它,让它返回一个函数去处理剩下的参数。
var checkage = min => (age => age > min);var checkage18 = checkage(18);checkage18(20); //柯里化之前function add(x, y){ return х + у};add(1, 2) //3 //柯里化之后 function addX(y){ return function (x){ return х + у; }};addX(2)(1) // 3 // eg:const curry = (fn, arr = []) => (...args) => (arg => (arg.length === fn.length ? fn(...arg) : curry(fn, arg)))([ ...arr,...args ]); let curryTest = curry((a, b, c, d) => a + b + c + d);curryTest(1, 2, 3)(4); //返回10curryTest(1, 2)(4)(3); //返回10curryTest(1, 2)(3, 4); //返回10
函数的反柯里化
函数柯里化,是固定部分参数,返回一个接受剩余参数的函数,也称为部分计算函数,目的是 为了缩小适用范围,创建一个针对性更强的函数。
那么反柯里化函数,从字面讲,意义和用法跟函数柯里化相比正好相反,扩大适用范围,创建一个应用范围更广的函数。使本来只有特定对象才适用的法,扩展到更多的对象。
// 反柯里化Function.prototype.uncurring = function() { var self = this; return function() { var obj = Array.prototype.shift.call(arguments); return self.apply(obj, arguments); };}; var push = Array.prototype.push.unCurrying(), obj = {};push(obj, "first", "two"); console.log(obj); //事实上柯里化是一种“预加载”函数的方法,通过传递较少的参数,得到一个已经记住了这些参数的新函数,某种意义上讲,这是一种对参数的”缓存”,是一种非常高效的编写函数的方法
函数组合
纯函数以及如何把它柯里化写出的洋葱代码h(g(x)),为了解决函数嵌套的问题,我们需要用到“函数组合”
我们一起来用柯里化来改他,让多个函数像拼积木一样
const compose=(f, g)=> (x => f(<x));var first= arr => arr[0]; Var reverse = arr => arr.reverse();var last = compose(first, rreverse);ast([1,2,3,4,5]);函数组合子
- compose函数只能组合接受一个参数的函数,类似于filter、 map接受两个参数(投影函数:总是在应用转换操作,通过传入高阶参数后返回数组),不能被直接组合可以借助偏函数包裹后继续组合。
- 函数组合的数据流是从右至左,因为最右边的函数首先执行,将数据传递给下一个函数以此类推,有人喜欢另一种方式最左侧的先执行,我们可以实现pipe (可称为管道、序列)来实现。1它和compose所做的事情一样, 只不过交换了数据方向。
- 因此我们需要组合子管理程序的控制流。
- 命令式代码能够使用if-else和for这样的过程控制,函数式则不能。所以我们需要函数组合子。组合子可以组合其他函数数(或其他组合子),并作为控制逻辑单元的高阶函数,组合子通常不声明任何变量,也不包含任何业务逻辑,他们旨在管理函数程序执行流程,并在链式调用中对中间结果进行操作。
- 常见的组合子如下:
- 辅助组合子 无为(nothing) 、照旧(identity) 、默许(defaultTo) 、恒定(always)
- 函数组合子 收缩(gather) 、展开(spread) 、颠倒(reverse)左偏(partal) 、右偏(partialRight)、柯里化(urry)、弃离(tap)、交替(alt) 、补救(tryCatch) 、同时 (seq) 、聚集(converge) 、映射(map)、分捡(useWith) 、规约(reduce) 、组合(compose)
- 谓语组合子 过滤(filter) 、分组(group) 、排序(sort)
- 其它 组合子变换juxt
- 分属于SK1组合子。
Point Free
把一些对象自带的方法转化成纯函数,不要命名转瞬即逝的中间变量。
这个函数中,我们使用了str 作为我们的中间变量,但这个中间变量除了让代码变得长了一点以外是毫无意义的。
const f = str=> str.toUpperCase().split("");这种风格能够帮助我们减少不必要的命名,让代码保持简洁和通用。
声明式与命令式代码
命令式代码的意思就是,我们通过编写一条又一条指令去让计算机执行一些动作,这其中一般都会涉及到很多繁杂的细节。而声明式就要优雅很多了,我们通过写表达式的方式来声明我们想干什么,而不是通过一步一步的指示。
//命令式let CEOs = [];for(var i= 0; i< compaies.length;i++){ CEOs.push(companies[i].CEO) } //声明式let CEOs = companies.map(c => c.CEO);优缺点
- 函数式编程的一个明显的好处就是这种声明式的代码,对于无副作用的纯函数,我们完全可以不考虑函数内部是如何实现的,专注于编写业务代码。优化代码时,目 光只需要集中在这些稳定坚固的函数内部即可。
- 相反,不纯的函数式的代码会产生副作用或者依赖外部系统环境,使用它们的时候总是要考虑这些不干净的副作用。在复杂的系统中,这对于程序员的心智来说是极大的负担。
惰性求值,惰性链,惰性函数
_.chain(数据 ).map().reverse().value()惰性链可以添加一个输入对 象的状态,从而能够将这些输入转换为所需的输出操作链接在一起。与简单的数组操作不一样,尽管他是一个复杂的程序,但仍然可以避免创建任何变量,并且有效消除所有循环。且在最后调用value之前并不会真正的执行任何操作。这就是所谓的惰性链~
当输入很大但只有一个小的子集有效时,避免不必要的函数调用就是所谓的情性求值。惰性求值方法有很多如组合子(alt-类似于II先计算fun7如果返回值是false、 null、 undefined就不再执行fun2、memoization、shortcut funsion), 但是目的都是一样的,即尽可能的推迟求值,直到依赖的表达式被调用。
惰性函数很好理解,假如同一个函数被大量范围,并且这个函数内部又有许多判断来来检测函数,这样对于一个调用会浪费时间和浏览器资源,所有当第一次判断完成后,直接把这个函数改写,不在需要判断。
// .chain可以推断可优化点 如合并执行或存储优化//合并函数执行并压缩计算过程中使用的临时数据结构降低内存占用const trace = (msg) => console. log( msg);let square = (x) => Math.pow(x, 2);let isEven= (x) => x%2===0;//使用组合子跟踪square = R.compose(R. tap(( )=>trace( "map数组" )),square);isEven = R.compose(R. tap(( )=>trace("filter数组" )),isEven);const number = _.range(200);const result = _.chain( numbers ).map( square ).filter( isEven ).take(3 ).value( );console. log( result );//首先take( 3 )志担心前3个通过的map和filter的值//其实shortcut fusion技术把map和filter融合//_.compose( filter( isEven ),map( square) );// compose( filter(p1),filter(p2)) => filter((x)=>p1(x) && p2(x) ) //Lodash中其他带 有shortcutfus ion优化的函数.drop. .//_.drop 、_.dropRight、_.dropRightWhile、_.dropWhile // egconst alt = _.curry(( fun1, fun2,val ) => fun1(val) || fun2(val));const showStudent = _.compose(函数体1,alt(xx1,xx2 ) )showStudent({}) // egvar object = {a:"xx", b:2};var values =memoize(_.values);values(object);object.a = "hello"console.log( values.cache.get(object)); // egfunction createXHR(){ var xhr=null ; if( typeof XMLHttpRequest != 'undefined'){ xhr=new XMLHt tpRequest(); createXHR=function(){ return XMLHttpRequest(); } }else{ try{ xhr=new ActiveXObject( "Msxml2.XMLHTTP" ); createXHR= function(){ return new ActiveXObject( "Msxml2. XMLHTTP" ); } }catch(e){ try{ xhr =new ActiveXObject( "Microsoft .XMLHTTP" ); createXHR=function(){ return new ActiveXObject( "Microsoft . XMLHTTP" ); } }catch(e){ createXHR=function(){ return null } } } }}
高阶函数
函数当参数,把传入的函数做一个封装,然后返回这个封装函数,达到更高程度的抽象。
//命令式var add = function(a,b){ return a+ b;};function math(func,array){ return func(array[0],array[1]);};math(add,[1,2]); // 3
尾调用优化PTC
指函数内部的最后一个动作是函数凋用。该调用的返回値,直接返回給函数。。函数調用自身,称为递归。如果尾调用自身,就称为尾递归。递归需要保存大量的调用记录,很容易岌生桟溢出錯俣,如果使用尾递归优化,将递归变为循坏,那么只需要保存一个调用记录,这样就不会发生栈溢出错误了。
//不是尾逆旧,无法代化斐波那契数列function facoria(n) { if(n === 1) return 1 return n*facoria(n-1);} function facoria(n,total) { if(n === 1) return total return facoria(n-1,n*total);} // ES6强制使用尾递归普通递归时,内存需要记录调用的堆栈所出的深度和位置信息。在最底层计算返回值,再根据记录信息,跳回上一层级计算,然后再跳回更高一级,一次运行,直到最外层的调用函数。在CPU计算和内存会消耗很多,而且当深度过大时,会出现堆栈溢出。
整个计算过程是线性的,调用一次sum(x, total)后, 会进入下一个栈,相关的数据信息和跟随进入,不再放在堆栈上保存。当计算完最后的值之后,直接返回到最上层的sum(5,0)。这能有效的防止堆栈溢出。在ECMAScript 6,我们将迎来尾递归优化,通过尾递归优化,javascript代 码在解释成机器码的时候,将会向while看起,也就是说,同时拥有数学表达能力和while的效能。
尾递归调用的问题
- 尾递归的判断标准是函数运行[最后一步] 是否调用自身,而不是是否在函数的[最后一行) 调用自身,最后一行调用其他函数并返回叫尾调用。
- 按道理尾递归调用调用栈永远都是更新当前的栈帧而已,这样就完全避免了爆栈的危险。但是现如今的浏览器并未完全支持原因有二:①在引擎层面消除递归是一个隐式的行为,程序员意识不到。②堆栈信息丢失了开发者难已调试。
- 既然浏览器不支持我们可以把这些递归写成while
蹦床函数
这里借用蹦床函数这个例子对的递归,尾递归,相互递归的一些使用心得。
递归
我们知道,es5是没有尾递归优化的,所以在递归的时候,如果层数太多,就会报“Maximum call stack size exceeded”的错误。就连下面这个及其简单的递归函数都会报“Maximum call stack size exceeded”的错误。
function haha(a) { if(!a) return a; return haha(a-1);} haha(100); //输出0haha(12345678); //输出“Maximum call stack size exceeded”为什么会报“Maximum call stack size exceeded”的错误?
我觉得原因是在每次递归调用的时候,会把当前作用域里面的基本类型的值推进栈中,所以一旦递归层数过多,栈就会溢出,所以会报错。
- js中的栈只会储存基本类型的值,比如:number, string, undefined, null, boolean。
- 为什么在调用下一层递归函数的时候没有释放上一层递归函数的作用域?因为在回来的时候还需要用到里面的变量。
尾递归
怎么优化上面的情况呢?方法是使用尾递归。有尾递归优化的编译器会把尾递归编译成循环的形式,如果没有尾递归优化,那就自己写成循环的形式。如下面的例子所示:
//尾递归函数,返回一个函数调用,并且这个函数调用是自己function haha(a, b) { if(b) return b; return haha(a, a-1);} //优化成循环的形式function yaya(a) { let b = a; while(b) { b = b - 1; }}需要注意的是,看上面尾递归的代码,有一点很重要,就是用一个b变量来存上一次递归的值。这是尾递归常用的方法。另外,其实上面尾递归的代码不需要变量b,但为了便于说明,所以我加上了变量b。
相互递归
但是关于递归还有一种形式,就是相互递归,如下面的代码所示:
function haha1(a) { if(!a) return a; return haha2(a-1);} function haha2(a) { if(!a) return a; return haha1(a-1);} haha1(100); //输出0haha1(12345678); //输出Maximum call stack size exceeded可以看到,当相互递归层数过多的时候,也会发生栈溢出的情况。
蹦床函数
蹦床函数就是解决上面问题的方法。
首先我们改写上面的相互递归函数:
function haha1(a) { if(!a) return a; return function() { return haha2(a-1); }} function haha2(a) { if(!a) return a; return function() { return haha1(a-1); }}这个改写就是建立一个闭包来封装相互递归的函数,它的好处是由于不是直接的相互递归调用,所以不会把上一次的递归作用域推进栈中,而是把封装函数储存在堆里面,利用堆这个容量更大但读取时间更慢的储存形式来替代栈这个容量小但读取时间快的储存形式,用时间来换取空间。
我们尝试使用一下上面的函数:
haha1(3)(); //输出一个函数haha1(3)()()(); //输出0通过上面的示例可以看到,如果参数不是3而是很大的一个数字的时候,我们就需要写很多个括号来实现调用很多次。为了简便,我们可以把这种调用形式写成函数,这就是蹦床函数。如下所示:
function trampoline(func, a) { let result = func.call(func, a); while(typeof result === 'function') { result = result(); } return result;}基本原理是一直调用,直到返回值不是一个函数为止。
最后来使用蹦床函数:
trampoline(haha1, 12345678); //过一会儿就输出0由于储存在堆中,所以耗时较长,过了一会儿才会输出0,但是并没有报栈溢出的错误。
闭包
如下例子,虽然外层的makePowerFn函数执行完毕,栈上的调用帧被释放,但是堆上的作用域并不被释放,因此power依旧可以被powerFn函数访问,这样就形成了闭包
function makeP owerFn(power) { function powerFn(base) { return Math.pow(base, power); }, return powerFn; }var square = makePowerFn(2);square(3); // 9
范畴和容器
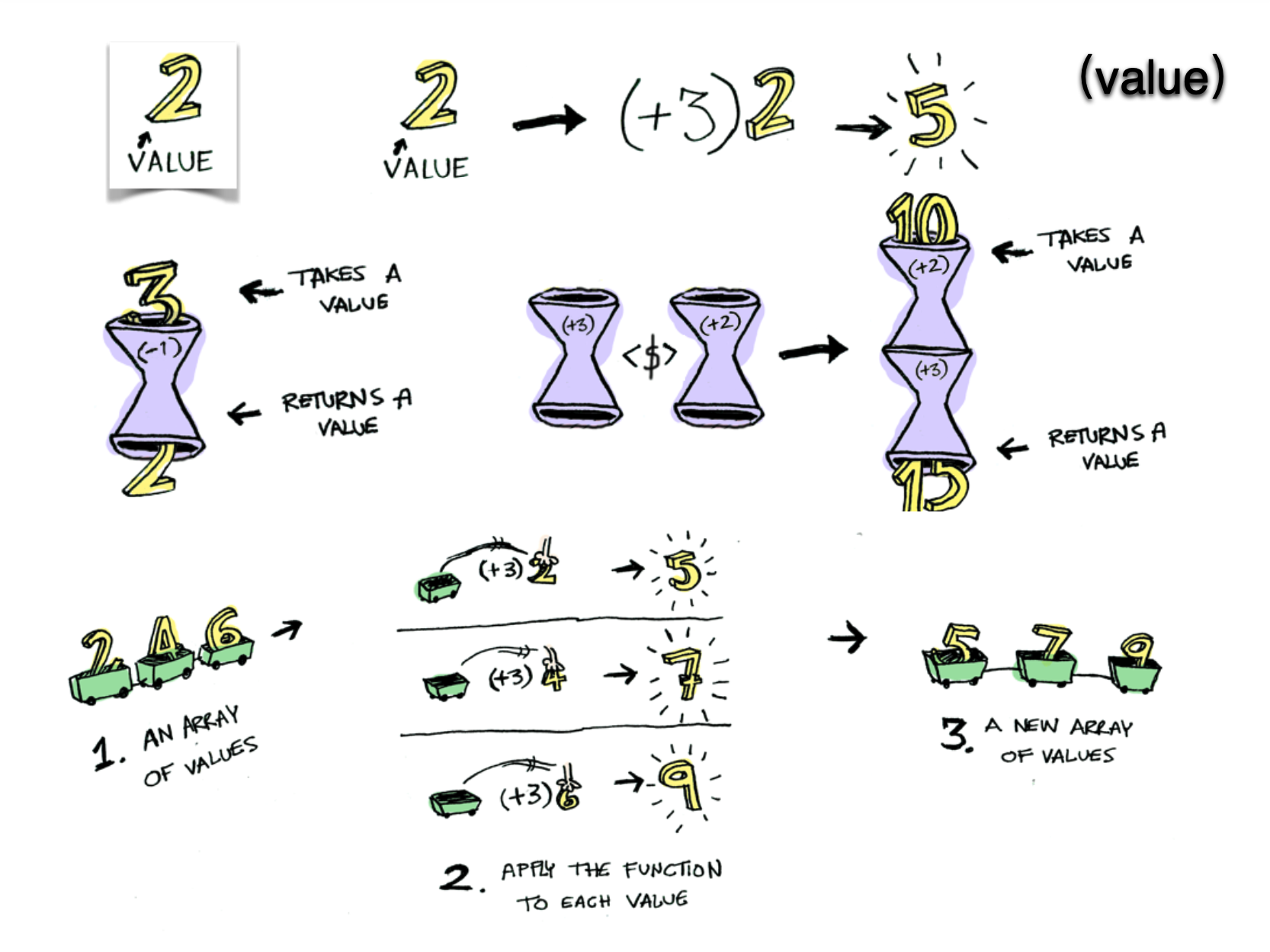
- 我们可以把”范畴”想象成是一个容器,里面包含两样东西。值(value) 、值的变形关系,也就是函数。
- 范畴论使用函数,表达范畴之间的关系。
- 伴随着范畴论的发展,就发展出一整套函数的运算方法。这套方法起初只用于数学运算,后来有人将它在计算机上实现了,就变成了今天的”函数式编程”。
- 本质上,函数式编程只是范畴论的运算方法,跟数理逻辑、微积分、行列式是同一类东西,都是数学方法,只是 碰巧它能用来写程序。为什么函数式编程要求函数必须是纯的,不能有副作用?因为它是一种数学运算,原始目的就是求值,不做其他事情,否则就无法满足函数运算法则了。
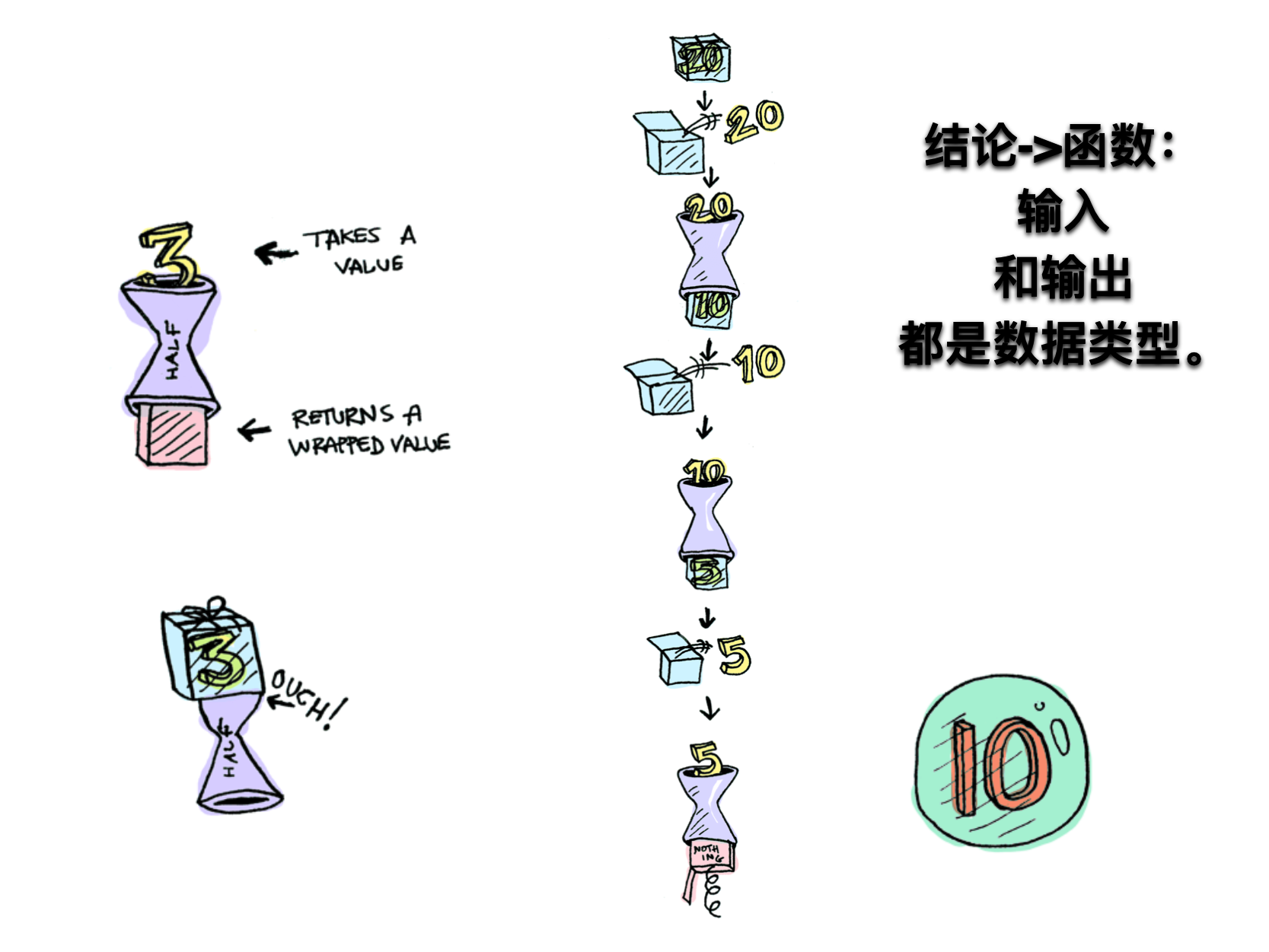
- 函数不仅可以用于同一个范畴之中值的转换,还可以用于将一个范畴转成另一个范畴。这就涉及到了函子(Functor) 。
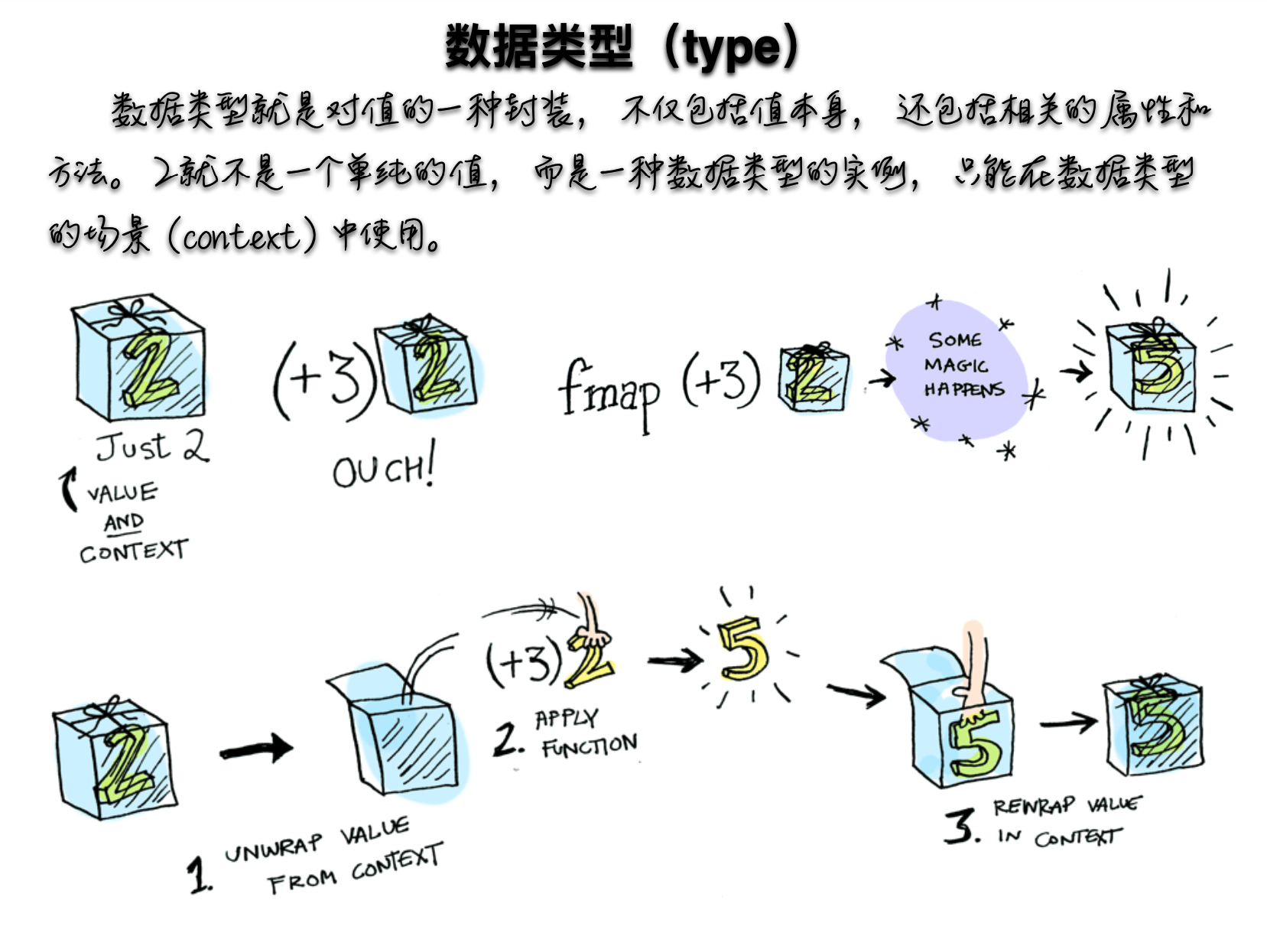
- 函子是函数式编程里面最重要的数据类型,也是基本的运算单位和功能单位。它首先是一种范畴,也就是说,是一个容器,包含了值和变形关系。比较特殊的是,它的变形关系可以依次作用于每一个值,将当前容器变形成另一个容器。
容器、functor(函子)
$(...)返回的对象并不是一个原生的DOM对象,而是对于原生对象的一种封装,这在某种意义上就是一个“容器”(但它并不函数式)。
Functor (函子)遵守一些特定规则的容器类型。
Functor 是一个对于函数调用的抽象, 我们赋予容器自己去调用函数的能力。把东西装进一个容器,只留出一个接口map给容器外的函数,map一个函数时,我们让容器自己来运行这个函数,这样容器就可以自由地选择何时何地如何操作这个函数,以致于拥有惰性求值、错误处理、异步调用等等非常牛掰的特性。
函子的代码实现
var Container = function(x){ this.__value = x;} //函数式编程一般约定,函子有一个of方法Container.of = x => new Container(x)//Container.of("abcd")//一般约定,函子的标志就是容器具有map的方法。该方法将容器里面的每一个值,映射到另一个容器Container.prototype.map = function(f){ return Container.of(f(this.__value));} Container.of(3) .map(x => x+1) //结果Container(4) .map(x => "Result" + x) // 结果Container("Result is 4") // es6class Functor{ constructor(val){ this.val = val } map(f){ return new Functor(f(this.val)) }} (new Functor(2)).map(function(two){ return two + 2;})//Functor(4) //上面代码中,Functor是一个函子,它的map方法接受函数f作为参数,然后返回一个新的函子,里面包含的值是被f处理过的(f(this.va))一般约定,函子的标志就是容器具有map方法。该方法将容器里面的每一个值,映射到另一个容器。,上面的例子说明,函数式编程里面的运算,都是通过函子完成,即运算不直接针对值,而是针对这个值的容器----函子。函子本身具有对外接口(map方法),各种函数就是运算符,通过接口接入容器,引发容器里面的值的变形。因此,学习函数式编程,实际上就是学习函子的各种运算。由于可以把运算方法封装在函子里面,所以又衍生出各种不同类型的函子,有多少种运算,就有多少种函子。函数式编程就变成了运用不同的函子,解决实际问题。Pointed函子
- 函子只是一个实现了map契约的接口。Ponited函子是一个函子的子集。
- 生成新的函子的时候,用了new命令。这实在太不像函数式编程了,因为new命令是面向对象编程的标志。函数式编程一般约定,函子有一个f方法,用来生成新的容器。
Functor.of = function(val) { return new Functor(val);} Functor.of(2).map(function(two){ return two + 2;})// Functor(4)//数字称为一个Pointed函子Maybe函子
- Maybe用于处理错误和异常。函子接受各种函数,处理容器内部的值。这里就有一个问题容器内部的值可能是一个空值(比如ull)而外部函数未必有 处理空值的机制,如果传入空值,很可能就会出错。
Functor.of(null).map(function(s){ return s.toUpperCase();})//TypeErrorclass Maybe extends Fucntor{ map(f){ return this.val ? Maybe.of(f(this.val)):Maybe.of(null); }} Maybe.of(null).map(function(s){ return s.toUpperCase()}) // Maybe(null)
错误处理、Either、 AP
Either函子
- 1.我们的容器能做的事情太少了,try/catch/throw 并不是‘纯’的,因为它从外部接管了我们的函数,并且在这个函数出错时抛弃了它的返回值分支
- Promise是可以调用catch来集中处理错误的。
- 事实上Either并不只是用来做错误处理的,它表示了逻辑或,范畴学里的coproduc。
- 条件运算if...else是最常见的运算之一,函数式编程里面,使用Either 函子表达。Either函子内部有两个值:左值(Left) 和右值(Right) 。右值是正常情况下使用的值,左值是右值不存在时使用的默认值。
- Left和Right唯一的区别就在于map方法的实现,Right.map 的行为和我们之前提到的map函数一样。但是Left.map就很不同了:它不会对容器做任何事情,只是很简单地把这个容器拿进来又扔出去。这个特性意味着,Left 可以用来传递一个错误消息。
class Either extends Functor{ constructor(left,right){ this.left = left this.right = right } map(f){ return this.right ? Either.of(this.left,f(this.right)) : Either.of(f(this.left),this.right); }} Either.of = function(left,right){ return new Either(left,right);} var addOne = function(x){ return x+1;} Either.of(5,6).map(addOne);//Either(5,7)Either.of(1,null).map(addOne);//Either(2,null)Either.of({address:"xxx"},currentUser.address).map(updateField);//替代try .. catch var Left = function (x){ this.__value = x} var Right = function(x){ this.__value = x} Left.of = function(x){ return new Left(x);} Right.of = function(x){ return new Right(x);} //这里不同Left.prototype.map = function(f){ return this} Right.prototype.map = function(f){ return Right.of(f(this.__value));} var getAge = user => user.age ? Right.of(user.age) : Left.of("Error"); getAge({name:"stark",age:21}).map(age=> "Age is" + age)// Right("Age is 32") getAge({name:"stark"}).map(age=>"Age is" + age)// Left("Error") // Left可以让调用链中任意一环的错误立刻返回到调用链的尾部,这给我们错误处理带来了很大的方便,再也不用一层又一层的try...catch。Ap函子
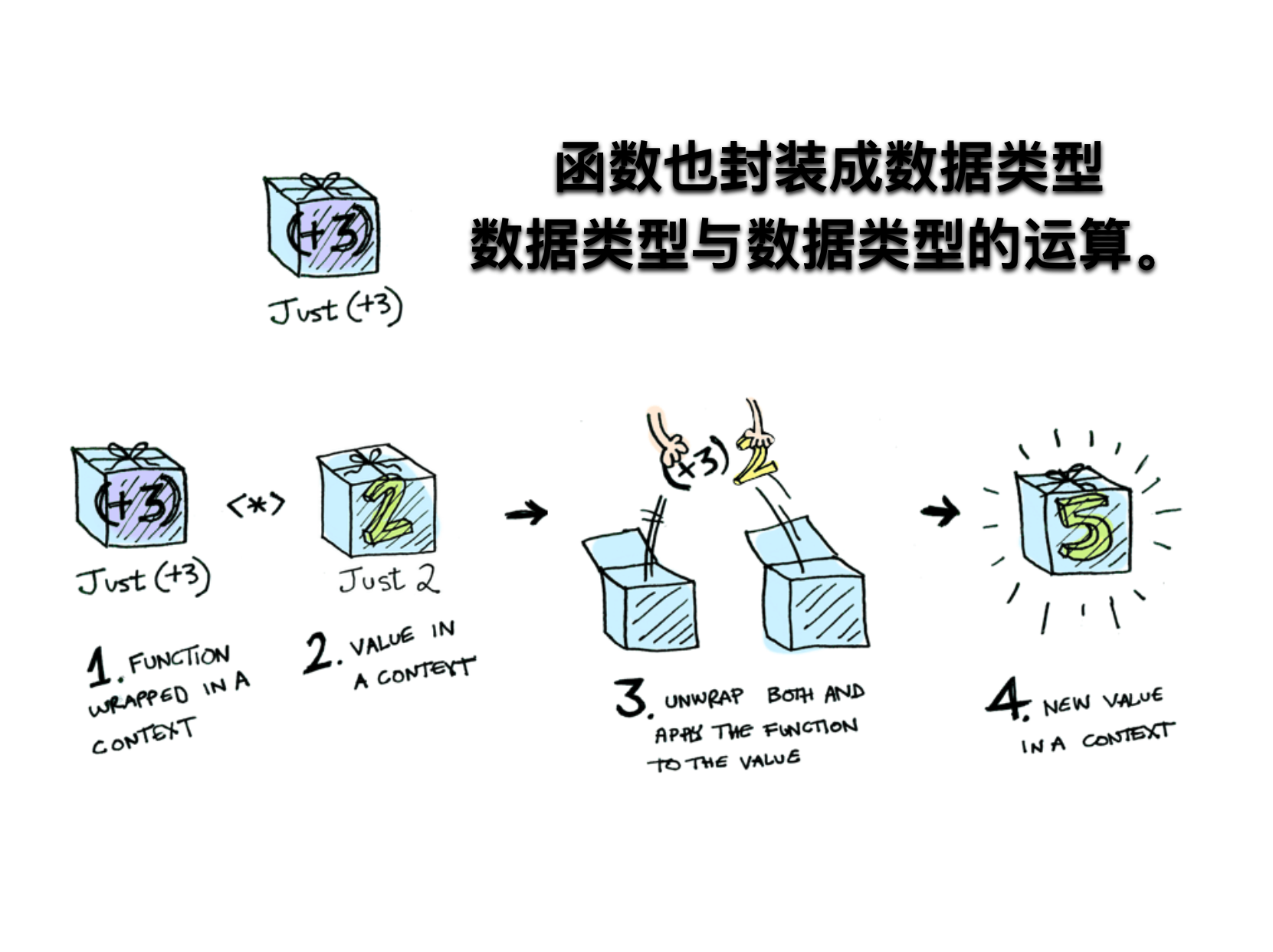
函子里面包含的值,完全可能是函数。我们可以想象这样一种情况,一个函子的值是数值,另一个函子的值是函数。
class Ap extends Functor{ ap(F){ return Ap.of(this.val(F.val)); }} class Ap extends Functor{ ap(F){ return Ap.of(this.val(F.val)); }} AP.of(addTwo).ap(Functor.of(2));
IO
真正的程序总要去接触肮脏的世界。
function readCocalStorage(){ return Window.localStorage;}IO跟前面那几个Functor 不同的地方在于,它的_ value 是一个函数。它把不纯的操作(比如10、网络请求、DOM)包裹到一个函数内,从而延迟这个操作的执行。所以我们认为,10包含的是被包裹的操作的返回值。
IO其实也算是情性求值。
IO负责了调用链积累了很多很多不纯的操作,带来的复杂性和不可维护性
IO函子
var fs = require("fs")var readFile = function(filename){ return new IO(function(){ return fs.readFileSync(filename,'utf-8') })} readFile("./a.txt").flatMap(tail).flatMap(print)//等同于readFile("./a.txt").chain(tail).chain(print)
Monad
Monad就是一种设计模式,表示将一个运算过程,通过函数拆解成互相连接的多个步骤。你只要提供下一步运算所需的函数,整个运算就会自动进行下去。
Promise就是一种Monad。
Monad让我们避开了嵌套地狱,可以轻松地进行深度嵌套的函数式编程,比如10和其它异步任务。
记得让上面的IO集成Monad
// Monad函子的作用是,总是返回一个单层的函子它有一个flatMap方法,与map方法作用相同,唯一的区别是如果生成了一个嵌套函子,它会取出后者内部的值,保证返回的永远是一个单层的容器,不会出现嵌套的情况//如果函数f返回的是一个函子,那么this.map(f)就会生成一个嵌套的函子。所以,join方法保证了flatMap方法总是返回个单层的函子。这意味着嵌套的函子会被铺平(tlatten) Maybe.of( Maybe.of( Maybe.of({name:'jack',age:21}) )) class Monad extends Functor{ join(){ return this.val; } flatMap(f){ return this.map(f).join(); }}
函子的工作#
思考
见识到了Maybe、Either、 I0这三种强大的Functor, 在链式调用、惰性求值、错误捕获、输入输出中都发挥着巨大的作用。事实上Functor远不止这三种。但依然有问题困扰着:
- 如何处理嵌套的Functor呢? (比如Maybe(I0(42))
- 如何处理一个由非纯的或者异步的操作序列呢?
思考函数装箱和拆箱。。。。
当下函数式编程比较火热的库#
- RxJs
- cycleJs
- lodashJs、lazy
- underscoreJs
- ramdaJs
实际应用场景#
易调试、热部署、并发
- 函数式编程中的每个符号都是const 的,于是没有什么函数会有副作用。谁也不能在运行时修改任何东西,也没有函数可以修改在它的作用域之外修改什么值给其他函数继续使用。这意味着决定函数执行结果的唯一因素就是它的返回值,而影响其返回值的唯一因素就是它的参数。
- 函数式编程不需要考虑”死锁" (dead(ock) ,因为它不修改变量,所以根本不存在"锁"线程的问题。不必担心一个线程的数据,被另一个线程修改,所以可以很放心地把工作分摊到多个线程,部署"并发编程”(concurrency)
- 函数式编程中所有状态就是传给函数的参数,而参数都是储存在栈上的。这一特性让软件的热部署变得十分简单。只要比较一下正在运行的代码以及新的代码获得一个diff, 然后用这个diff更新现有的代码,新代码的热部署就完成了。
单元测试
- 严格函数式编程的每一个行号都是对直接量或者表达式结果的引用,没有函数产生副作用。因为从未在某个地方修改过值,也没有函数修改过在其作用域之外的量并被其他函数使用(如类成 员或全局变量)。这意味着函数求值的结果只是其返回值,而惟一影响其返回值的就是函数的参数。
- 这是单元测试者的梦中仙境(wet dream)。对被测试程序中的每个函数,你只需在意其参数,而不必考虑函数调用顺序,不用谨慎地设置外部状态。所有要做的就是传递代表了边际情况的参数。如果程序中的每个函数都通过了单元测试,你就对这个软件的质量有了相当的自信。而命令式编程就不能这样乐观了,在Java或C++中只检查函数的返回值还不可够我们还必须验证这个函数可能修改了的外部状态。
总结和补充
- 函数式编程不应被视为灵丹妙药。相反,它应该被视为我们现有工具箱的一个很自然的补充它带来了更高的可组合性,灵活性以及容错性。现代的JavaScript库 已经开始尝试拥抱函数式编程的概念以获取这些优势。Redux 作为一种FLUX的变种实现,核心理念也是状态机和函数式编程。
- 这里介绍了纯函数、柯里化、Point Free、 声明式代码和命令式代码的区别,只要记住「函数对于外部状态的依赖是造成系统复杂性大大提高的主要原因J,从及「让函数尽可能地纯净」就行了。然后介绍了「容器」的概念和Maybe、 Either、 10这三个强大的Functor。是的,大多数人或许都没有机会在生产环境中自已去实现这样的玩具级Functor, 但通过了解它们的特性会让你产生对于函数式编程的意识。
- 软件工程上讲「没有银弹J ,函数式编程同样也不是万能的,它与烂大街的OOP样,只是一种编程范式而已。很多实际应用中是很难用函数式去表达的,选择POP亦或是其它编程范式或许会更简单。但我们要注意到函数式编程的核心理念,如果说OOP降低复杂度是靠良好的封装、继承、多态以及接口定义的话,那么函数式编程就是通过纯函数以及它们的组合、柯里化、Functor等技术来降低系统复杂度,而React、Rxjs、 Cycle.js 正是这种理念的代言。让我们一起拥抱函数式编程,打开你程序的大门!